

R语言概述
- R是属于GNU系统的一个自由、免费、源代码开放的软件,它是用于数据分析和可视化的软件功能的集成套件,是一个用于统计计算和统计制图的优秀工具。它可以在各种UNIX平台、Windows和MacOS上编译并运行。 R是统计领域广泛使用的诞生于1980年左右的S语言的一个分支,R是一个类似于S语言的GNU项目,可以将R视为S的不同实现,该项目是由约翰·钱伯斯及其同事在AT&T贝尔实验室开发的。R与S一样,都是围绕一种真正的计算机语言设计的,它允许用户通过定义新功能来添加其他功能。系统的大部分本身是用S的R语言编写的,这使用户可以轻松地遵循所选择的算法。对于计算量大的任务,可以在运行时链接和调用C,C ++和Fortran代码。高级用户可以编写C代码来直接操纵R对象。R和S存在一些区别,但是用S编写的许多代码在R的环境下都不会改变。S语言通常是统计方法论研究的首选工具,R语言提供了一种开放源代码的途径来参与该活动。
- R可以轻松制作出精心设计的具有出版质量的图表,其中包括需要的数学符号和公式。R提供了各种各样的统计信息(线性和非线性建模,经典统计检验,时间序列分析,分类,聚类等等)和图形技术,并且具有高度的可扩展性。许多用户将R视为统计软件,其实可以将R视为实现统计技术的环境。R可以通过包轻松扩展。R发行版提供了大约八种软件包,并且CRAN系列Internet网站还提供了更多软件包,涵盖了非常广泛的现代统计数据。R有自己的类似LaTeX的文档格式,可用于提供全面的文档,既可以在线使用多种格式,也可以使用硬拷贝。
- R是一个自由的、免费的、开源的软件。
- R可以轻松地从各种类型的数据源导入数据库,包括文本文件、数据库管理系统、统计软件,乃至专门的数据仓库。它同样可以将数据输出并写入这些系统中。
- R可以在Windows、UNIX、Mac OS X和Linux等多种平台上运行。
- R拥有强大的制图功能,提供了丰富的2D和3D图形库,能够生成从简单到复杂的各种图形。
- R更新迅速,囊括了许多先进的统计计算和前沿的统计方法。事实上,新方法的更新速度是以周来计算的,这是大多数统计软件达不到的。
- R可以连接到其他的高性能编程语言,如C++、Python、SAS和SPSS等。这样你可以在熟悉的语言编程环境中加入R的功能。
R的基本使用
赋值操作
在R语言中,标准赋值运算符是“<-”,并非传统的“=”。R语言也允许使用“=”为对象赋值,不过并不建议使用它。
> x<-0:10 #创建一个等差数列向量> x[1] 0 1 2 3 4 5 6 7 8 9 10区分大小写
R语言对大小写很敏感,即X和x的含义是不同的,同一字母的大小写代表不同的变量对象。
> x<-1:10> X 错误: 找不到对象'X'> x[1] 1 2 3 4 5 6 7 8 9 10‘+’提示符
当输入命令没有完整前,R会以“+”作为提示符,提醒用户该命令还未结束。这时,将命令输入完整,则提示符会变成“>”。
> x<-10-++ 2> x[1] 8示例
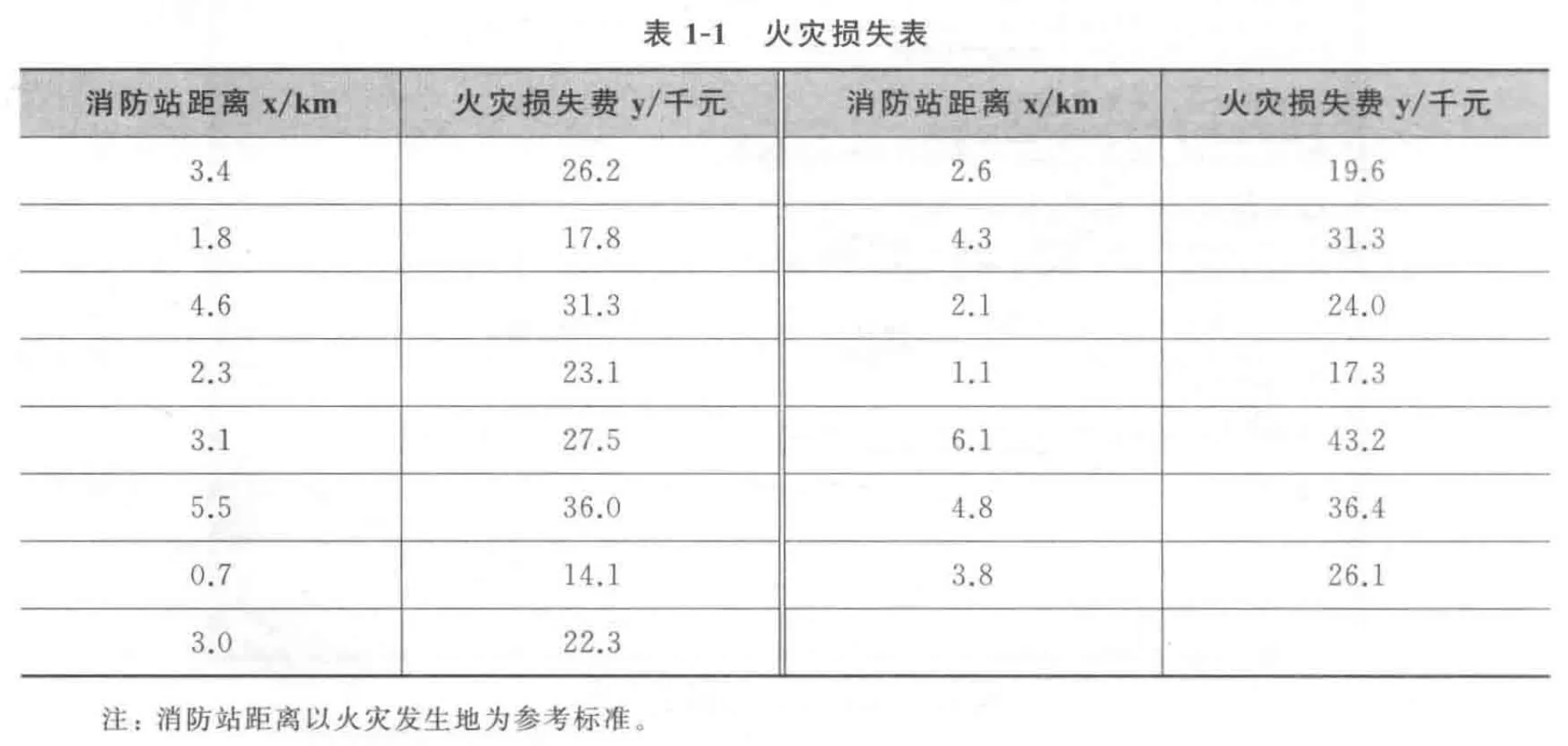
>x<-c(3.4,1.8,4.6,2.3,3.1,5.5,0.7,3.0,2.6,4.3,2.1,1.1,6.1,4.8,3.8)>y<-c(26.2,17.8,31.3,23.1,27.5,36.0,14.1,22.3,+19.6,31.3,24.0,17.3, 43.2,36.4,26.1)>mean(y) #mean()函数求取均值[1] 26.41333>sd(y) #sd()函数求取方差[1]8.068976>cor(x, y) #cor()函数计算相关系数[1] 0.9609777>plot (x,y) #plot()绘制散点图>q() #函数q()结束会话并允许退出R语言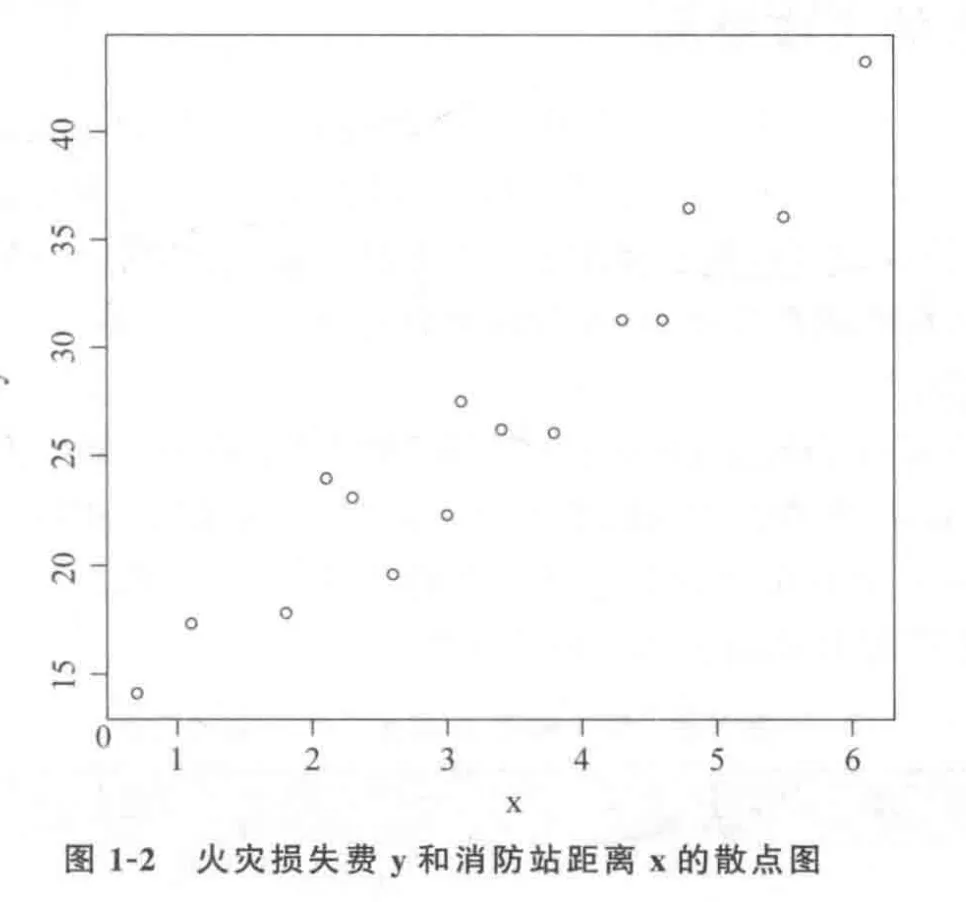
从代码中可以看到,火灾损失的平均费用为26.413元,标准差为8.069元,火灾发生地
离消防站距离与火灾损失之间存在较强的线性关系(相关度为0.96)。这种关系也可以通过散点图看出来,即火灾地离消防站越远,所造成的火灾损失费用就会越高
输入与输出
启动R软件后将默认开始一个交互式的会话,从键盘接受输入并从屏幕进行输出。也可以处理写在一个脚本文件(一个包含了R语句的文件)中的命令集并直接将结果输出到多类目标中。
1.输入
函数source(“filename”)可在当前会话中执行一个脚本。如果文件名中不包含路径,R 语言将假设此脚本在当前工作目录中。举例来说,source(“myscript.R”)将执行包含在文件myscript.R中的R语句集合
2.文本输出
函数sink(“filename”)将输出重定向到文件filename中。默认情况下,如果文件已经存在,则它的内容将被覆盖。使用参数append=TRUE 可以将文本追加到文件后,而不是覆盖它。参数split=TRUE 可将输出同时发送到屏幕和输出文件中。不加参数调用命令sink()将仅向屏幕返回输出结果。
3.图形输出
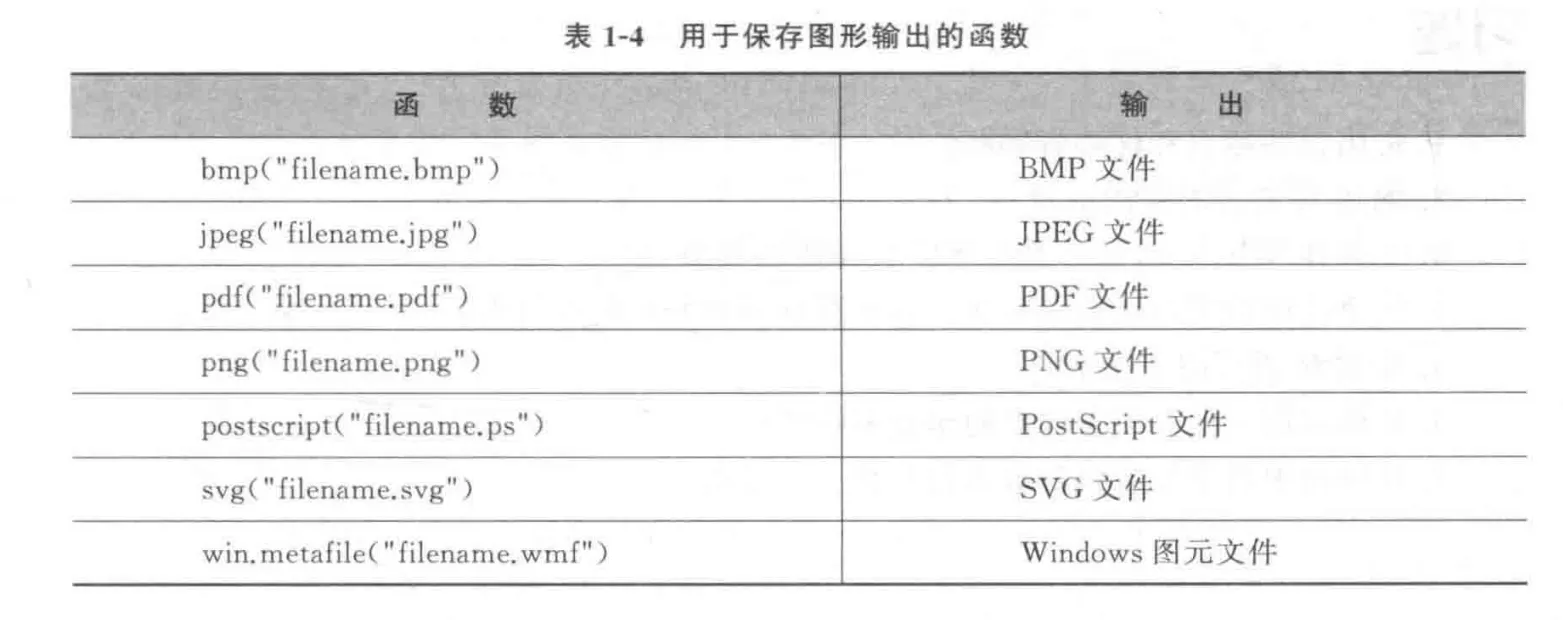
虽然sink()可以重定向文本输出,但它对图形输出没有影响。要重定向图形输出,使用表1-4中列出的函数即可,最后使用dev.off()将输出返回到终端
分支语句
if语句
if、if…else…、else if
> #if语句> print("请输入您的心率值(单位:次/分):")[1] "请输入您的心率值(单位:次/分):"> value<-scan()1: 1002:Read 1 item> if(value>=60&value<=100){print("正常值")}else{print("异常值,请监测心率")}[1] "正常值"> print("请输入您的血压测量值(单位:mmHg),收缩压(SBP)和舒张压(DBP)为:")[1] "请输入您的血压测量值(单位:mmHg),收缩压(SBP)和舒张压(DBP)为:"> value<-scan()1: 100 1503:Read 2 items> if(value[1]<120&value[2]<80){print("正常值")}else+ if(value[1]<140&value[2]<90){print("正常高值")}else+ {print("高血压")}[1] "高血压"> #向量化的逻辑表达式> y<-c(3,8)> fruit<-10*y> fruit<-fruit*ifelse(y>5,0.9,1)> fruit[1] 30 72switch语句
> #switch语句> switch(2,mean(1:10),sum(1:10),max(1:10),min(1:10)) #执行数字对应表达式[1] 55> switch(2*2,mean(1:10),sum(1:10),max(1:10),min(1:10))[1] 1> pra<-switch("gamma",alpha=1,beta=sqrt(4),gamma={a<-sin(pi/2);4*a^2})> pra[1] 4> you.like<-'eat'> out<-switch(you.like,drink='water',meat='beef',fruit='apple',vegetable='cabbage')> outNULL循环语句
> #循环语句> repeat{+ message("请投骰子!")+ action<-sample(1:6,1)+ message("action=",action)+ if(action=="6") break+ }请投骰子!action=4请投骰子!action=6> repeat{+ message("BMI index!")+ bmi<-sample(c(18.5,24,28,32),1)+ if(bmi==18.5){+ message("Quietly skipping to the next iteration")+ next+ }+ message("BMI=",bmi)+ if(bmi==32) break+ }BMI index!BMI=32> i<-1> sum<-0> repeat{+ sum = sum+i+ i = i+1+ if(i>100){+ print(sum)+ break+ }+ }[1] 5050While语句
> #while语句> action<-sample(1:6,1)> message("action=",action)action=3> while(action!="6"){+ message("please continue...")+ action<-sample(1:6,1)+ message("action=",action)+ }please continue...action=3please continue...action=5please continue...action=4please continue...action=6> message("Game over!")Game over!> i<-1> sum<-0> while(i<=100){sum=sum+i;i=i+1}> print(sum)[1] 5050for循环
> #for循环语句> n<-c(2,5,10)> for(i in n){+ x<-i^2+ cat('power(',i,'):',x,'\n')+ }power( 2 ): 4power( 5 ): 25power( 10 ): 100> n<-5> x<-array(0,dim=c(n,n))> for(i in 1:n){+ for(j in 1:n){+ x[i,j]<-1/(i+j-1)+ }+ }>> print(x)[,1] [,2] [,3] [,4] [,5][1,] 1.0000000 0.5000000 0.3333333 0.2500000 0.2000000[2,] 0.5000000 0.3333333 0.2500000 0.2000000 0.1666667[3,] 0.3333333 0.2500000 0.2000000 0.1666667 0.1428571[4,] 0.2500000 0.2000000 0.1666667 0.1428571 0.1250000[5,] 0.2000000 0.1666667 0.1428571 0.1250000 0.1111111
#replication高级循环
> bmi_fun<-function(){+ bmi<-sample(+ c('fat','weight', 'normal','light'),+ size=1,+ prob=c(0.1,0.3,0.4,0.2)+ )++ time<-switch (+ bmi,+ fat=rnorm(1,32,5),##rnorm正态分布(个数,均值,标准差)+ weight=rnorm(1,28,3),+ normal=rnorm(1,24,3),+ light=rnorm(1,18.5,2)+ )++ names(time)+ time+ }> replicate(3,bmi_fun())[1] 21.19540 24.39278 15.58931自定义函数
> plot.f<-function(f,a,b){val<-seq(a,b,length=100);plot(val,f(val))}> plot.f(sin,0,2*pi)> plot.f(cos,0,2*pi)
> vms<-function(x){+ xx=rev(sort(x))+ xx=xx[1:5]+ mean(xx)+ return(list(xba=mean(xx),top5=xx))+ }> x<-c(3,9,1,4,7,5,3)> vms(x)$xba[1] 5.6$top5[1] 9 7 5 4 3数据集
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
数据类型
R语言中,可以处理的数据类型有
- 数值型 numeric
- 字符型 character
- 逻辑型 logical
- 复数型 (虚数)
- 原生型 (字节)
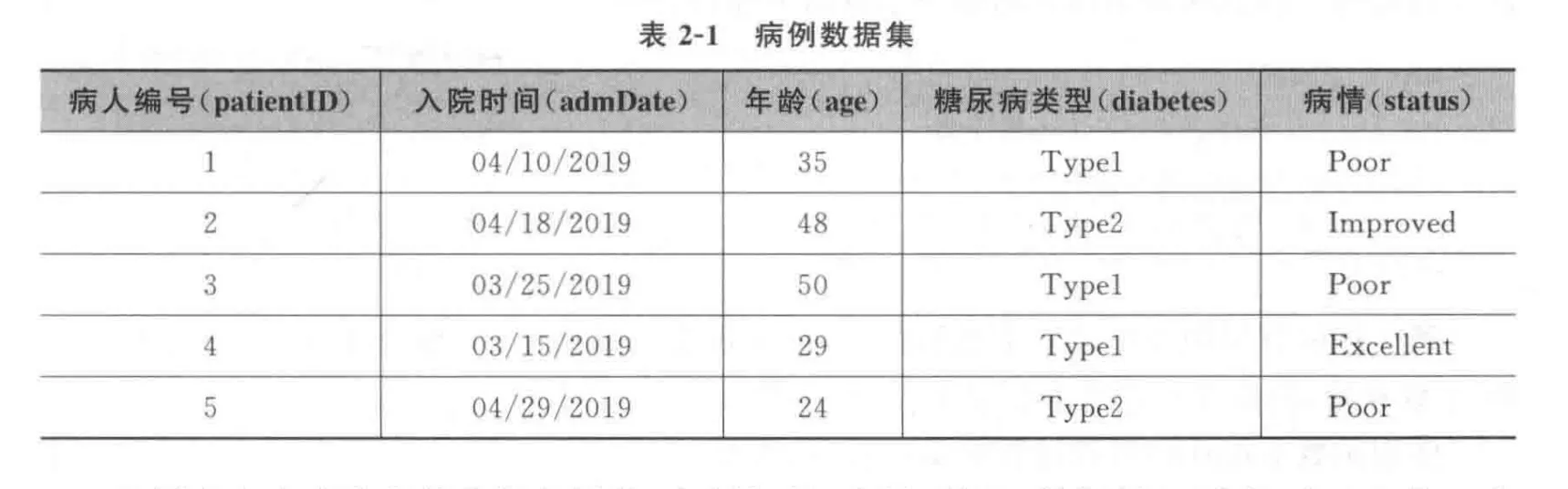
如上图表2-1中,patientID、admDate和age为数值型变量,而diabetes和status则为字符型变量。如果再细分一下:patientID是实例标识符,admDate含有日期数据,diabetes和status分别是名义型和有序型变量。R语言将实例标识符称为rownames (行名),将类别型(包括名义型和有序型)变量称为因子(factors)。
数据结构
R语言中提供了多种存储数据的对象类型,包括标量(R语言中的标量是由向量的形式表达,即只含一个元素的向量,多用于存储常量,可以说R语言中没有标量)、向量、矩阵、数组、数据框、列表
向量
声明
定义:向量是用于存储数值型、字符型或逻辑型数据的一维数组。单个向量中的数据必须保持相同的类型或模式(数值型、字符型或逻辑型)
创建方法:常见创建函数为c()
其他函数方法:查看数据类型用mode()、查看向量长度length()
创建向量
>a<-c(1,3,5,6,2,4,9)>a[1]1 3 5 6 2 4 9>b<-c("A","B", "C") #使用c函数创建向量>c<-c(TRUE, TRUE, FALSE,TRUE)>mode(a)[1] "numeric">mode(b)[1]"character">mode(c)[1]"logical"
>x<-12:60 #使用冒号创建向量>x[1] 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35[25] 36 3738 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59[49] 60>length(x)[1] 49seq()函数
可以生成等差序列、实数序列,并且可以指定步长
#格式一:seq(from=value1,to=value2,by=value3)> seq(1,5,0.5)[1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
#格式二:seq(length=value1,from=value2,by=value3)> seq(length=9,from=1,by=0.5) [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0rep()函数
创建重复元素的向量
> rep(1,10) [1] 1 1 1 1 1 1 1 1 1 1> rep(1:5,2) [1] 1 2 3 4 5 1 2 3 4 5> rep(c("male","female"),5) [1] "male" "female" "male" "female" "male" "female" "male" [8] "female" "male" "female"> rep(c("male","female"),each=5) [1] "male" "male" "male" "male" "male" "female" [7] "female" "female" "female" "female"> rep(c("S","M","L"),c(2,3,4))[1] "S" "S" "M" "M" "M" "L" "L" "L" "L"sequence()函数
创建一个连续的整数序列,每一个序列都以给定参数结尾
> sequence(4:5)[1] 1 2 3 4 1 2 3 4 5> sequence(c(10,5)) [1] 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5> sequence(c(1,10)) [1] 1 1 2 3 4 5 6 7 8 9 10> sequence(4:5)[1] 1 2 3 4 1 2 3 4 5> sequence(c(10,5)) [1] 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5> sequence(c(1:10)) [1] 1 1 2 1 2 3 1 2 3 4 1 2 3 4 5 1 2 3 4 5[21] 6 1 2 3 4 5 6 7 1 2 3 4 5 6 7 8 1 2 3 4[41] 5 6 7 8 9 1 2 3 4 5 6 7 8 9 10类型转换
> as.numeric(FALSE)[1] 0> as.numeric(TRUE)[1] 1> as.numeric("1")[1] 1> as.numeric("0")[1] 0> as.numeric("A")[1] NA> as.logical(0)[1] FALSE> as.logical(1)[1] TRUE> as.logical(2)[1] TRUE> as.logical("FALSE")[1] FALSE> as.logical("F")[1] FALSE> as.logical("T")[1] TRUE> as.character(1)[1] "1"> as.character(FALSE)[1] "FALSE"> as.character(TRUE)[1] "TRUE"向量元素选取
>x<-1:10>x[1] 1 2 3 4 5 6 7 8 9 101.通过下标取对应值
>x[5][1] 52.通过c()函数和下标取多值
>x[c(1,5,8,10)][1] 1 5 8 103.通过切片获取或删除
>x[2:5][1] 2 3 4 5>x[-2:-5][1] 1 6 7 8 9 10矩阵
声明
定义:矩阵是一个二维数组,与向量类似,矩阵中也仅能包含一种数据类型(数值型、字符型或逻辑型)。
创建方法:使用函数matrix()来创建矩阵,一般语法格式为
matrix(data=NA, nrow=1, ncol=1, byrow=FALSE, dimnames=NULL)
data包含了矩阵的元素,默认为NA;
nrow和ncol分别为行数和列数,默认值均为1;
byrow表示矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下按列填充;
dimnames为以字符型向量表示的行名和列名,默认为NULL
创建矩阵
1.按列填充
>x<-matrix(1:15,nrow=5,ncol=3) # 5*3矩阵 按列填充>x
[,1] [,2] [,3][1,] 1 6 11[2,] 2 7 12[3,] 3 8 13[4,] 4 9 14[5,] 5 10 152.按行填充
>a<-1:6>rnames<-c("r1","r2")>cnames<-c("c1","c2","c3")>x<-matrix(a,nrow=2,ncol=3,byrow=TRUE, # 2*3矩阵 按行填充 dimnames=list(rnames,cnames))>x
[c1] [c2] [c3][r1] 1 2 3[r2] 4 5 6矩阵合并
> m1<-matrix(1,nr=2,nc=2)> m2<-matrix(2,nr=2,nc=2)> rbind(m1,m2) #按行合并[,1] [,2][1,] 1 1[2,] 1 1[3,] 2 2[4,] 2 2> cbind(m1,m2) #按列合并[,1] [,2] [,3] [,4][1,] 1 1 2 2[2,] 1 1 2 2矩阵下标使用
通过使用下标和方括号,可以访问矩阵中的行、列或元素。
X[i,]表示矩阵x中的第i 行,X[,j]表示矩阵X中的第j列,X[i,j]表示矩阵x中的第i行、第j列元素,选择多行或多列时,下标i和j可为数值型向量
>x<-matrix(1:15,nrow=5,ncol=3) # 5*3矩阵 按列填充>x
[,1] [,2] [,3][1,] 1 6 11[2,] 2 7 12[3,] 3 8 13[4,] 4 9 14[5,] 5 10 15
>x[2,][1] 2 7 12>x[,3][1] 11 12 13 14 15>x[5,3][1] 15>x[c(1,5),c(1,2,3)]
[,1] [,2] [,3][1,] 1 6 11[5,] 5 10 15数组
声明
定义:数组(array)与矩阵类似,但是维数可以大于2。像矩阵一样,数组中的数据也只能拥有一种模式。
创建方法:使用array()函数创建数组,语法格式如下:
array(data=NA, dim=length(data), dimnames=NULL)
data包含了数组的数据;
dim是各维长度组成的数值型向量;
dimnames是可选的、各维度名称标签的列表。
创建数组
>dim1<-c("R1", "R2", "R3")>dim2<-c("c1", "C2", "C3")>dim3<-c("M1", "M2", "M3")>z<-array(1:27, dim=c(3,3,3), dimnames=list(diml,dim2, dim3))>z
,, M1 C1 C2 C3R1 1 4 7R2 2 5 8R3 3 6 9
,, M2 C1 C2 C3R1 10 13 16R2 11 14 17R3 12 15 18
,, M3 C1 C2 C3R1 19 22 25R2 20 23 26R3 21 24 27首先创建了3个向量,分别表示数组中各维度的名称标签。然后创建了一个数据为1~27的3x3x3的数组,数组中的元素按列填充。
选取数组元素
1.获取目标单一值
#延用上代码块内容>z[1,2,3] #M3中第一行第二列[1] 222.通过切片截取向量
>z[1:2,1:2,2:3] #M2和M3的第一行至第二行,第一列至第二列
,, M2 c1 c2r1 10 13r2 11 14,, M3 c1 c2r1 19 22r2 20 23
>z[,,2] #M2全体元素#略>z[,2,2] #M2第二行全体元素#略数据框
声明
定义:数据框是R语言中最常处理的数据结构,它可以将不同的数据类型结构组合在一起。数据框的维数是二维
创建方法:数据框可以使用函数data.frame()创建:
data.frame(col1,col2,co13,…)
列向量col1、col2、col3等可为任何类型(如数值型、字符型或逻辑型等)
创建数据框
>patientID<-c(1,2,3,4,5)>age<-c(35,48,50,29,24)>diabetes<-c("Type1", "Type2", "Type1", "Type1", "Type2")>status<-c("Poor", "Improved", "Poor", "Excellent", "Poor")>patientdata<-data.frame(patientID, age, diabetes, status)>patientdata
patientID age diabetes status1 1 35 Typel Poor2 2 48 Type2 Improved3 3 50 Type1 Poor4 4 29 Type1 Excellent5 5 24 Type2 Poor同一列的数据类型必须唯一,如 patientID和age是数值型向量,diabetes和status是字符型向量。首先给各个变量赋值,然后使用函数data.frame()将多个类型不同的列放到一起组成数据框。
选取数据框元素
数据框元素的选取与矩阵类似,可以使用下标或下标向量,也可以直接使用列名或列名向量
>patientdata[1:2,1:4] #第一行至二行的第一至四列数据
patientID age diabetes status1 1 35 Typel Poor2 2 48 Type2 Improved
>patientdata[1:2,c(2:3)] #第一行至二行的第二至三列数据>patientdata[1:2,c("age","diabetes")] #第一行至二行的第二至三列数据#略
>patientdata$age #获取age全部内容[1] 35 48 50 29 24第四个语句patientdata $ age 表示 patientdata 数据框中的变量age,记号$是用来选取一个给定数据框中的某个特定变量
列表
声明
定义:列表(list)是R语言的数据结构中最为复杂的一种。一般来说,列表是数据对象的有序集合,可以包含向量、矩阵、数组、数据框,甚至是另外一个列表
创建列表:可以使用函数list()创建列表
list (object1, object2, ……)
对象(object)可以是目前为止讲到的任何结构。还可以为列表中的对象命名:
list (namel=object1, name2=object2,……)
创建列表
>a<-"My List" #创建一个包含字符串、向量、矩阵、数组、数据框的列表>b<-c("Simon", "Lucy", "Andy", "James")>c<-c(185,168,160,180)>d<-matrix(1:12,nrow=3)>z<-array(1:12, dim=c(2,3,2))>mydata<-data.frame(name=b,height=c)>mylist<-list(title=a, name=b, height=c, d, z, mydata)
>mylist$title[1] "My List"
$name[1] "Simon" "Lucy" "Andy" "James"
$height[1] 185 168 160 180
[[4]] [,1] [,2] [,3] [,4][1,] 1 4 7 10[2,] 2 5 8 11[3,] 3 6 9 12
[[5]],, 1 [,1] [,2] [,3][1,] 1 3 5[2,] 2 4 6,,2 [,1] [,2] [,3][1,] 7 9 11[2,] 8 10 12
[[6]] name height1 Simon 1852 Lucy 1683 Andy 1604 James 180本例创建了一个列表,包含6个成分:一个字符串、一个字符型向量、一个数值型向量、一个矩阵、一个数组以及一个由字符型向量和数值型向量组成的数据框。
访问列表
访问列表的元素,可以使用方括号和双重方括号访问,两种方法所代表的含义不同,还
可以直接使用成分的名称访问
>mylist[2]$name[1] "Simon" "Lucy" "Andy" "James">mylist["name"]$name[1] "Simon" "Lucy" "Andy" "James">mylist[["name"]]>mylist[[2]]>mylist$name数据的输入
键盘输入数据
最简单的输入数据的方式就是键盘输入,有两种常见的方式:用R语言内置的文本编辑器和直接在代码中嵌入数据(前面介绍数据结构的创建就是在代码中嵌入数据)。
- 第1步:创建一个空数据框(或矩阵),其中变量名和变量的模式需与理想中的最终数据集一致。
- 第2步:针对这个数据对象调用文本编辑器,输入数据,并将结果保存回此数据对象中。
mydata<-data.frame(age=numeric(0),gender=character(0), weight=numeric(0))
mydata<-edit(mydata)
- 第3步:在如图2-1所示的编辑器上添加数据。单击列的标题,可以修改变量名和变量类型(数值型、字符型)。还可以通过单击未使用列的标题来添加新的变量。编辑器关闭后,结果会保存到之前赋值的对象中(mydata)
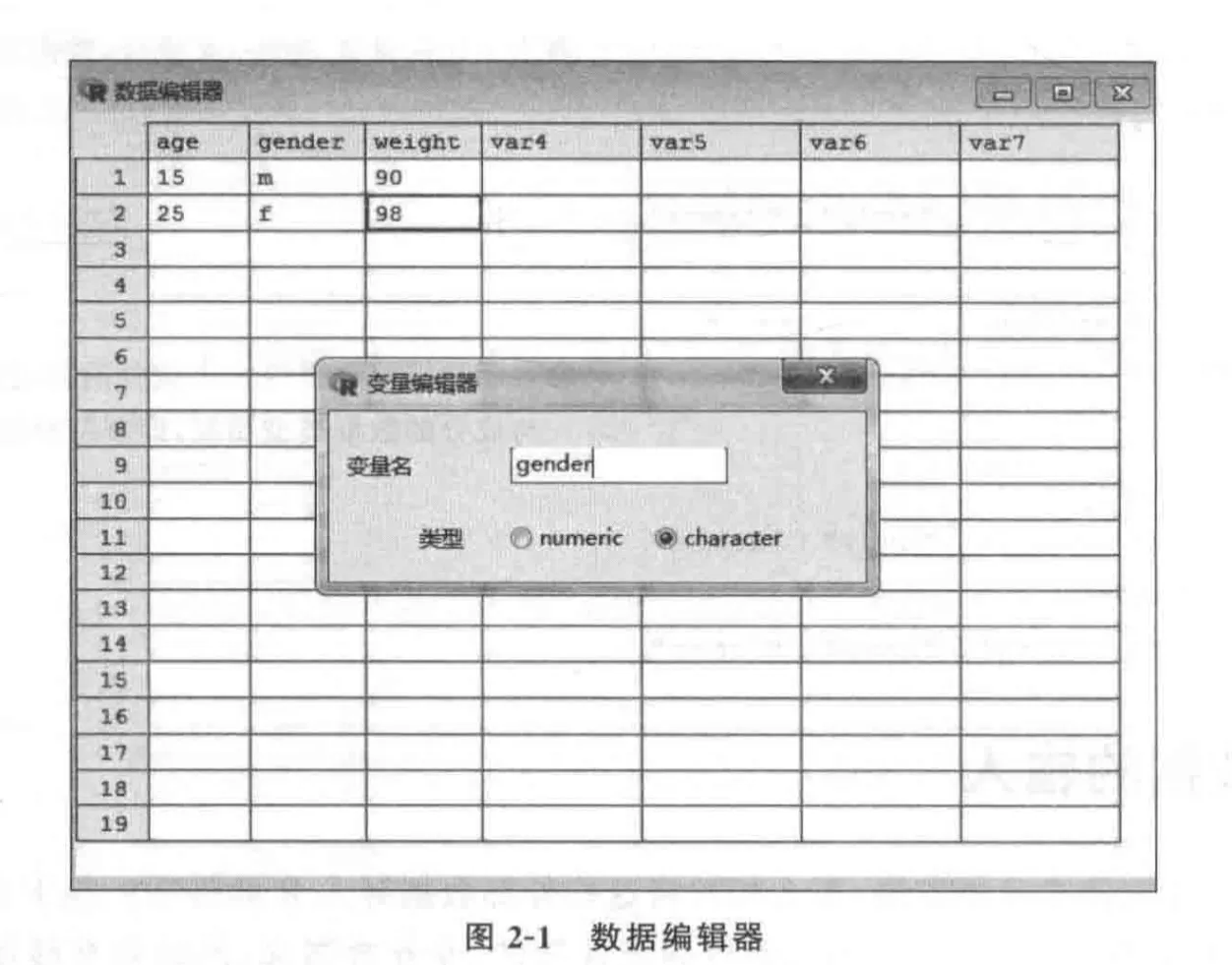
带分隔符的文本文件数据
从带分隔符的文本文件导入数据
其语法如下:
mydataframe <-read.table(file, options)
其中,file是一个带分隔符的ASCII文本文件,options是控制如何处理数据的选项。
Excel数据
读取一个Excel文件的最好方式,就是在Excel中将其导出为一个逗号分隔文件(csv),并使用232节描述的方式将其导入R软件中。
用函数 read.xlsx()导入一个工作表到一个数据框中。最简单的格式是read.xlsx(file,n),其中file是Excel工作簿的所在路径,n则为要导入的工作表序号。在Windows系统中导人一个工作表的代码如下。
library(x1sx)workbook<-"c:/myworkbook.xlsx"mydataframe <-read.xlsx(workbook, 1)以上代码表示从位于C盘根目录的工作簿 myworkbook.xlsx中导入了第一个工作表,并将其保存为一个数据框 mydataframe。
其他方法
SPSS数据、SAS数据、Stata数据
R语言数据分析与可视化P18页
基本绘图
图形简介
入门绘画
attach(mtcars) #mtcars是R语言内置数据集plot(wt,mpg,xlab="wt / t",ylab="mpg / Miles per gallon")abline(lm(mpg~wt)) #绘制最优拟合线detach(mtcars) # 解除捆绑首句绑定数据框mtcars。第二句调用函数plot()绘制了一幅散点图,横轴表示车身重量,纵轴表示每加仑行驶的英里数。第三句向图形添加了一条最优拟合线。最后一句解除对数据框的绑定。
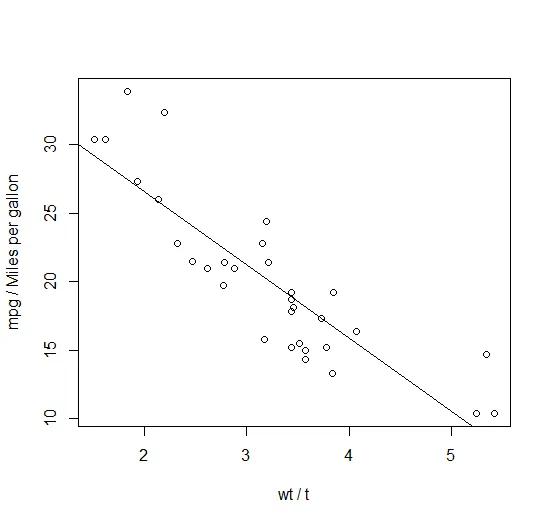
打开或关闭多个图形窗口
创建一幅新图形时,通常现有的图形窗口都会被新的图形覆盖
dev.new() #打开新窗口dev.off() #关闭窗口图形保存
a.使用代码保存图形,将绘图语句夹在开启目标图形设备的语句和关闭目标设备的语句之间即可
支持的格式有:pdf()、png()、bmp()、jpeg()、postscript()、tiff()和win.metafile()
pdf("graph1.pdf") #起始attach(mtcars)plot(wt, mpg)abline(lm(mpg~wt))detach(mtcars)dev.off() #终止b.通过图形用户界面来保存图形,鼠标右击图片保存或在图形窗口上方导航栏中选择“文件”、“另存为”
图形参数
- 我们可以通过修改图形参数来自定义一幅图形的多个特征,如符号、颜色、字体、坐标轴以及图例等,使其达到我们想要的效果。
- 常用的方式是使用**函数par()**来修改这些选项,其调用格式为par(optionname=value,optionname=name,…)。
- 当par()不加参数时,将返回当前图形参数设置的列表;
- 添加参数par(no.readonly=TRUE)将生成一个可以修改的当前图形参数列表。注意以这种方式设定的图形参数除非被再次修改,否则将会一直执行此参数设置,直到会话结束。
设置图形参数列表
attach(mtcars)opar<-par(no.readonly=TRUE) #图形设置保存在opar中(此处为默认的图形设置)par(pch=15,lty=2) #符号换成实心的方块,实线换成虚线plot(wt,mpg,xlab="wt / t",ylab="mpg / Miles per gallon")abline(lm(mpg~wt))par(opar) #一直执行此参数设置,直到会话结束(单窗口)绘画函数内直接添加图形参数
plot(wt,mpg,pch=15)abline(lm(mpg~wt),lty=2)符号与线条
| 参数 | 描述 |
|---|---|
| pch | 绘制点符号的样式 |
| cex | 符号的大小,默认大小为1,1.5表示放大为默认值的1.5倍,0.5表示缩小为默认值的50% |
| bg | 符号的内部填充色,仅限符号21~25 |
| lty | 线条类型 |
| lwd | 线条宽度,默认宽度为1 |
| col | 指定符号边框和线条的颜色 |
dev.new()plot(wt,mpg,pch=22,col=2,bg=8,cex=0.8, xlab="wt/t",ylab="mpg/Miles per gallon")abline(lm(mpg~wt),lty=2,lwd=2,col=3)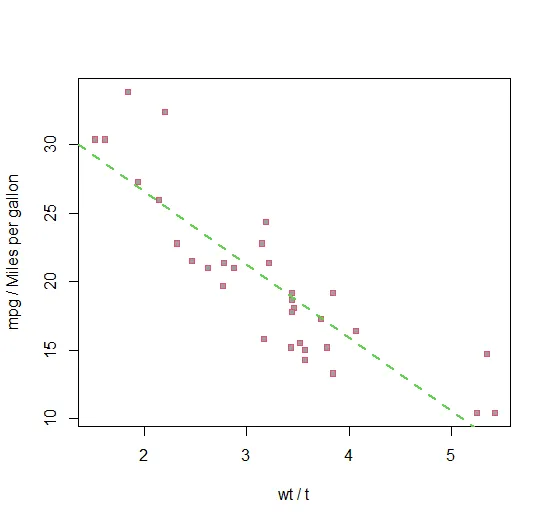
颜色
参数col除了上述的可以设置点、线的颜色,还可以设置图像、坐标轴、文字等的颜色
| 参数 | 描述 |
|---|---|
| col | 默认的绘图颜色 |
| col.axis | 坐标轴刻度文字的颜色 |
| col.lab | 坐标轴标签的颜色 |
| col.main | 标题的颜色 |
| col.sub | 副标题的颜色 |
| fg | 图形的前景色 |
| bg | 图形的背景色 |
在R中,可以通过颜色下标、颜色名称、十六进制的颜色值、RGB值或HSV值来确定颜色。例如: col=1、col=“white”、col=“#FFFFFF”、col=rgb(1,1,1)、col=hsv(0,1,1)
函数rgb()是基于红-绿-蓝生成的颜色,hsv() 是基于色相-饱和度-亮度值生成的颜色
函数colors()可以生成657中颜色名称,然后可以通过这些名称,使用参数col=颜色名称,来设定我们想要的颜色。
par(col="red",col.axis="blue",col.lab="black")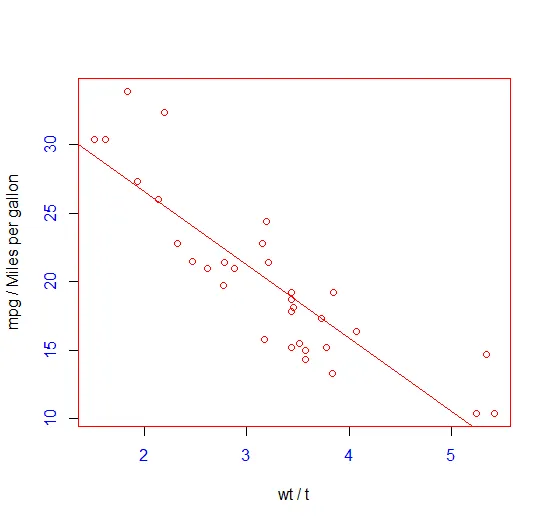
文本属性
文本属性包括指定字号、字体和字样
字体大小
| 参数 | 描述 |
|---|---|
| cex | 字体大小,默认大小为1。1.5表示放大为默认值的1.5倍,0.5表示缩小为默认值的50% |
| cex.axis | 坐标轴刻度文字的缩放倍数。类似于cex |
| cex.lab | 坐标轴标签(名称)的缩放倍数。类似于cex |
| cex.main | 标题的缩放倍数。类似于cex |
| cex.sub | 副标题的缩放倍数。类似于cex |
字体字样
| 参数 | 描述 |
|---|---|
| font | 整数。用于指定绘图使用的字体样式。1=常规,2=粗体,3=斜体,4=粗斜体,5=符号字体(以Adobe符号编码表示) |
| font.axis | 坐标轴刻度文字的字体样式 |
| font.lab | 坐标轴标签(名称)的字体样式 |
| font.main | 标题的字体样式 |
| font.sub | 副标题的字体样式 |
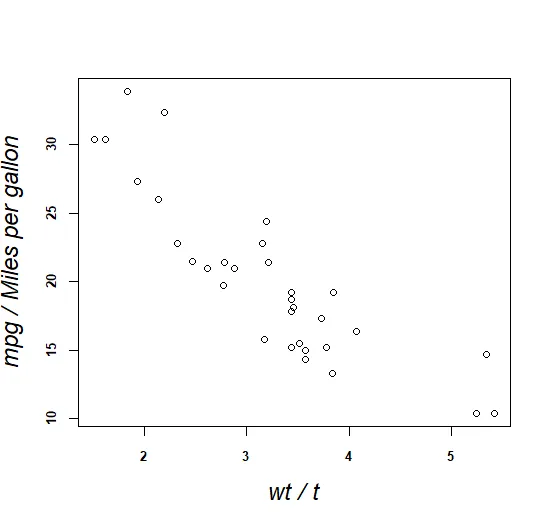
par(font.lab=3,cex.lab=1.5,cex.axis=0.8,font.axis=2)表示之后创建的所有图形的坐标轴标签(名称)字体样式为斜体、大小扩大为默认文本大小的1.5倍,坐标轴刻度文字字体样式为粗体、大小缩小为默认文本大小的80%
图形尺寸和边界尺寸
R语言中,还可以使用参数来控制图形尺寸和边界大小
| 参数 | 描述 |
|---|---|
| pin | 以英寸表示的图形尺寸(宽和高) |
| mai | 以数值向量表示的边界大小,顺序为“下、左、上、右”(顺时针),单位为英寸 |
| mar | 以数值向量表示的边界大小,顺序为“下、左、上、右”,单位为英分*。默认值为c(5, 4, 4, 2) + 0.1 |
par(pin=c(3,4),mai=c(1,1,1,.5))生成一幅3英寸宽、4英寸高、上下边界为为1英寸、左边界为1英寸、右边界为0.5英寸的图形
attach(mtcars)opar<-par(no.readonly=TRUE)par(pin=c(2,3)) #设置宽高par(lwd=2,cex=0.8) #设置线条宽度和符号大小par(font.axis=3,cex.axis=0.8) #设置坐标刻度字体样式和字体大小par(font.lab=2,cex.lab=1.2) #设置坐标轴标签的字体样式和大小plot(wt,mpg,pch=20,col="red",xlab="wt / t",ylab="mpg / Miles per gallon") #设置符号样式abline(lm(mpg~wt),lty=2) #设置线条类型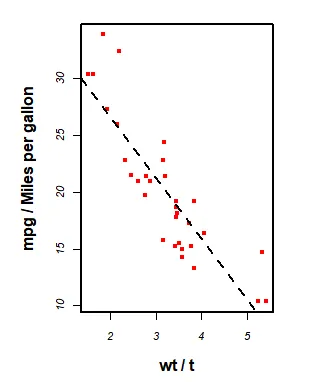
添加文本、自定义坐标轴和图例
许多高级绘图函数(例如plot、hist、boxplot)还允可以自行设定坐标轴和文本标注选项。例如,添加标题(main)、副标题(sub)、坐标轴标签(xlab、ylab)并指定了坐标轴范围(xlim、ylim)等
plot(wt,mpg,pch=2,col="red",main="Scatterplot of wt vs. mpg", # 主标题sub="one", # 副标题xlab="车重 / t", # X标签ylab="每加仑行驶英里数 / Miles per gallon", # Y标签xlim=c(0,10), # X刻度范围ylim=c(0,50)) # Y刻度范围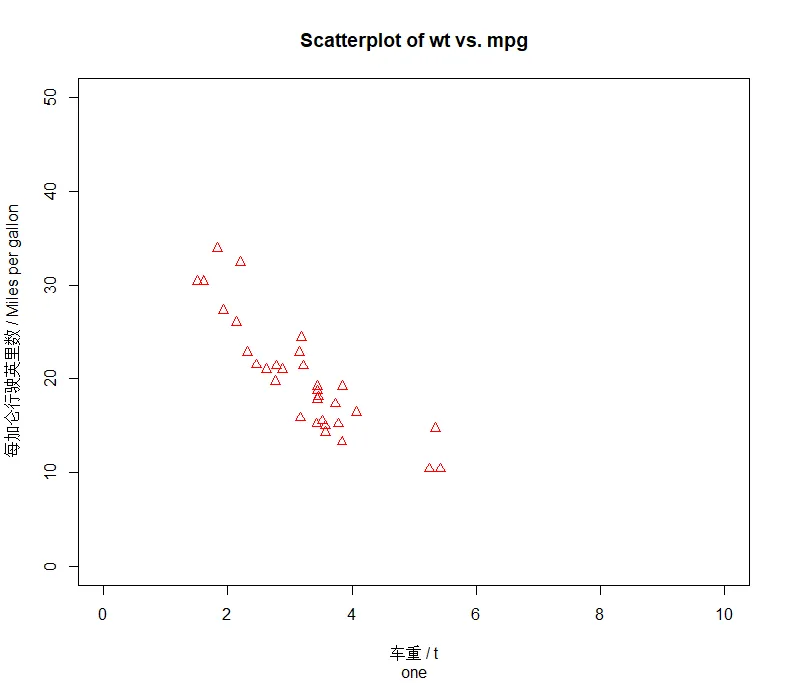
标题
**函数title()**可以为图形添加标题、副标题以及坐标轴标签
title(main="main title", sub="subtitle", xlab="x-axis label", ylab="y-axis label")函数title()还可以指定各选项的字体、大小和颜色
font.main、cex.main、col.main、font.sub、cex.sub、col.sub、font.lab、cex.lab、col.lab
title(main="My Title",col.main="red",font.main=2, # 生成红色且字体为粗体的标题sub="My Subtitle", col.sub="black", # 黑色的副标题xlab="x", ylab="y",col.lab="green", cex.lab=0.8) # 大小缩小为默认大小80%的绿色x轴、y轴标签坐标轴
axis()函数可以自定义坐标轴
axis(side, at=, labels=, pos=, lty=, col=, las=, tck=, ...)创建自定义坐标轴时,应当禁用高级绘图函数自动生成的坐标轴。使用参数axes=FALSE将禁用全部坐标轴(包括坐标轴框架线,除非你添加了参数frame.plot=TRUE)。参数xaxt=“n”和yaxt=“n”将分别禁用X轴或Y轴(会留下框架线,只是去除了刻度)
| 选项 | 描述 |
|---|---|
| side | 一个整数,表示在图形的哪一侧绘制坐标轴(1=下,2=左,3=上,4=右) |
| at | 一个数值型向量,表示需要绘制刻度线的位置 |
| labels | 一个字符型向量,表示置于刻度线旁边的文字标签(如果为 NULL,则将直接使用 at 中的值) |
| pos | 坐标轴线绘制位置的坐标(即与另一条坐标轴相交位置的值) |
| lty | 线条类型 |
| col | 轴线和刻度线颜色 |
| las | 标签是否平行于(=0)或垂直于(=2)坐标轴 |
| tck | 刻度线的长度,以相对于绘图区域大小的分数表示(负值表示在图形外侧,正值表示在图形内侧,0表示禁用刻度,1 表示绘制网格线);默认值为–0.01 |
| … | 其他图形参数 |
height<-c(155,157,160,163,166,169,172,175,179,182)weight<-c(58,59,60,61,62,63,64,65,66,67)plot(height,weight,type="b",pch=16,col="red", lty=2,xaxt="n",yaxt="n",ann=FALSE) # 禁止自动生成的坐标轴axis(1,at=height,labels=height) #横坐标axis(2,at=weight,labels=weight,las=2) #纵坐标title(xlab="height / cm",ylab="weight / kg")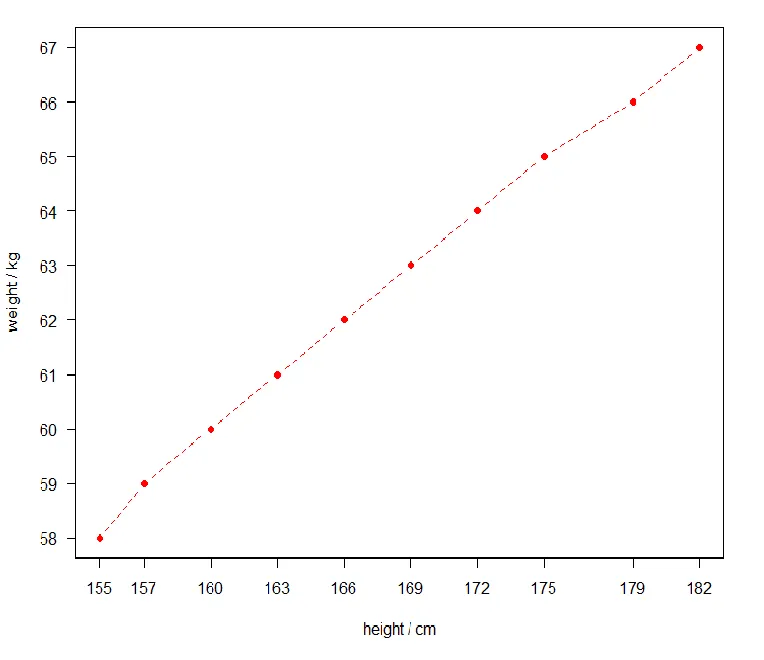
参考线
**函数abline()**可以为图形添加参考线,也可以指定其他图形参数(如线条类型、颜色和宽度)
abline(a = NULL, b = NULL, h = NULL, v = NULL, …)
a:常数项,b:斜率,h:水平线,v:垂直线
abline(h=c(1,3,5),v=4,col="green")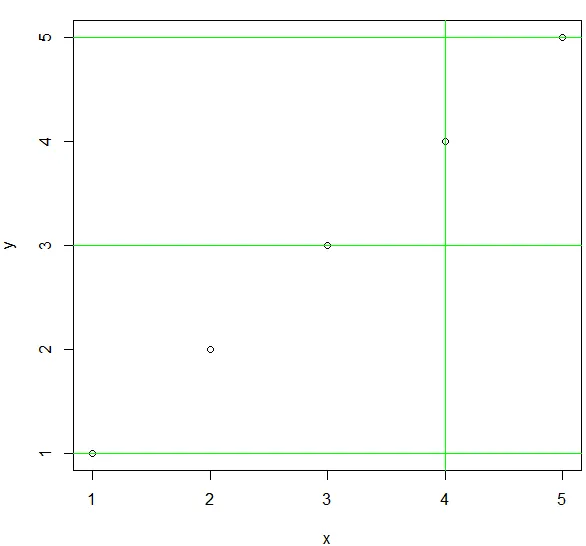
图例
**函数legend()**用来添加图例
| 选项 | 描述 |
|---|---|
| x,y | 指定图例的位置。也可以执行 locator(1),然后通过鼠标单击给出图例的位置,还可以使用关键字 bottom、bottomleft、left、topleft、top、topright、right、bottomright 或 center 放置图例 |
| inset | 当图例用关键词设置位置后,使用参数 inset=指定图例向图形内侧移动的大小(以绘图区域大小的分数表示) |
| legend | 图例标签组成的字符型向量 |
| title | 图例标题的字符串 |
| title.adj | 图例标题的相对位置,0.5为默认,在中间。0最左,1为最右。 |
| col | 图例中出现的点或线的颜色 |
| lty,lwd | 图例中线的类型与宽度 |
| pch | 图例中点的类型 |
| cex | 图例字符大小 |
| bty | 图例框是否画出,o为画出,默认为n不画出 |
| bg | bty != “n”时,图例的背景色 |
| text.col | 图例字体的颜色 |
| text.font | 图例字体的样式 |
| ncol | 图例中分类的列数 |
| horiz | 逻辑值,默认(horiz=FALSE)为垂直放置图例,horiz=TRUE将会水平放置图例 |
| … | 其他选项。请参考help(legend) |
| 选项 | 描述 |
|---|---|
| location | 文本的位置参数。可为一对 x、y 坐标,也可通过执行locator(1),使用鼠标交互式地确定摆放位置 |
| pos | 文本相对于位置参数的方位。1=下,2=左,3=上,4=右。如果指定了pos,就可以同时指定参数offset=作为偏移量,以相对于单个字符宽度的比例表示 |
| side | 指定用来放置文本的边。1=下,2=左,3=上,4=右。你可以指定参数 line=来内移或外移文本,随着值的增加,文本将外移。也可使用 adj=0 将文本向左下对齐,或使用 adj=1 右上对齐 |
age<-c(118,484,664,1004,1231,1372,1582)circumference_tree1<-c(30,58,87,115,120,142,145)circumference_tree2<-c(33,69,111,156,172,203,203)circumference_tree3<-c(30,51,75,108,115,139,140)
opar <- par(no.readonly=TRUE)par(font.lab=2,font.axis=3,cex.axis=0.8)
plot(age,circumference_tree1,type="b",pch=15,lty=1,col="red", ylim=c(0,250), xlab="Tree age / year", ylab="circumference ",xaxt="n")axis(1,at=seq(0,1600,200)) #刻度
lines(age,circumference_tree2,type="b",pch=16,lty=2,col="blue")lines(age,circumference_tree3,type="b",pch=17,lty=3,col="green")
legend("topleft",inset=.05,title="Tree Type", c("tree1","tree2","tree3"), lty=c(1, 2,3,4,5), pch=c(15,16,17), col=c("red","blue","green"))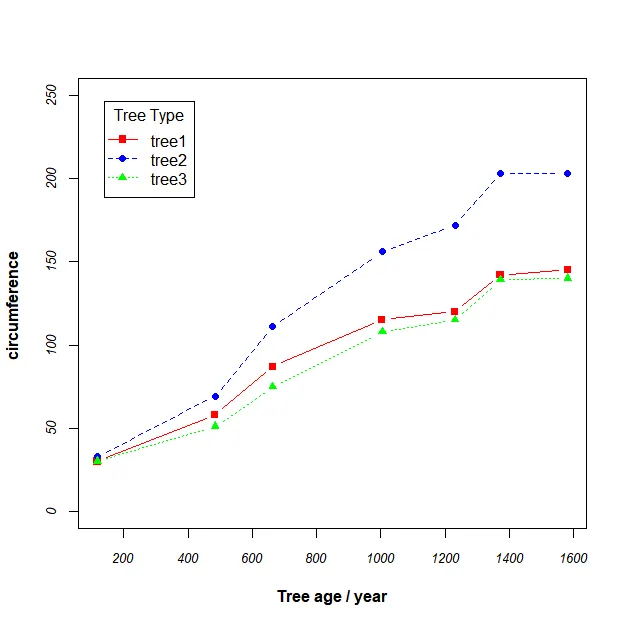
文本注释
使用函数text()和mtext()向图形中添加文本。
text()可向绘图区域内部添加文本,而mtext()则向图形的四个边界之一添加文本。
text(location,“text to place”, pos, …)
mtext(“text to place”, side, line=n, …)
散点图
基础函数plot()
散点图通常用来描述两个连续型变量间的关系,绘制基本散点图使用plot()函数
attach(mtcars)plot(wt,mpg,xlab="wt / t",ylab="mpg / Miles per gallon", pch=20,col="red")abline(lm(mpg~wt))散点图矩阵
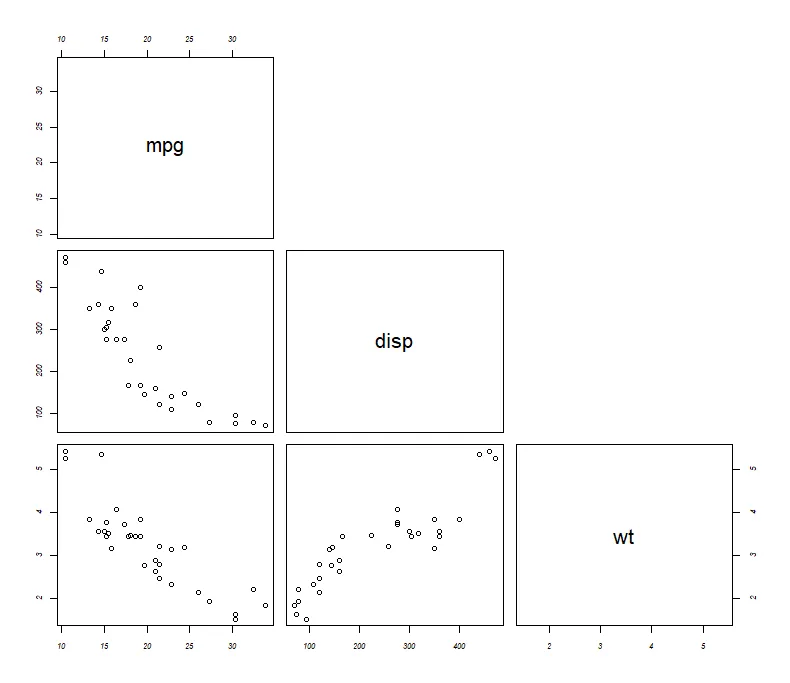
使用**函数pairs()**可以创建基础的散点图矩阵
pairs(formula, data,…)
formula:成对使用的一系列变量,data:表示将从中采集变量的数据集
pairs(~mpg+disp+wt, data=mtcars) # ①
pairs(~mpg+disp+wt, data=mtcars, upper.panel = NULL) # ②①所有指定变量间的二元相关关系
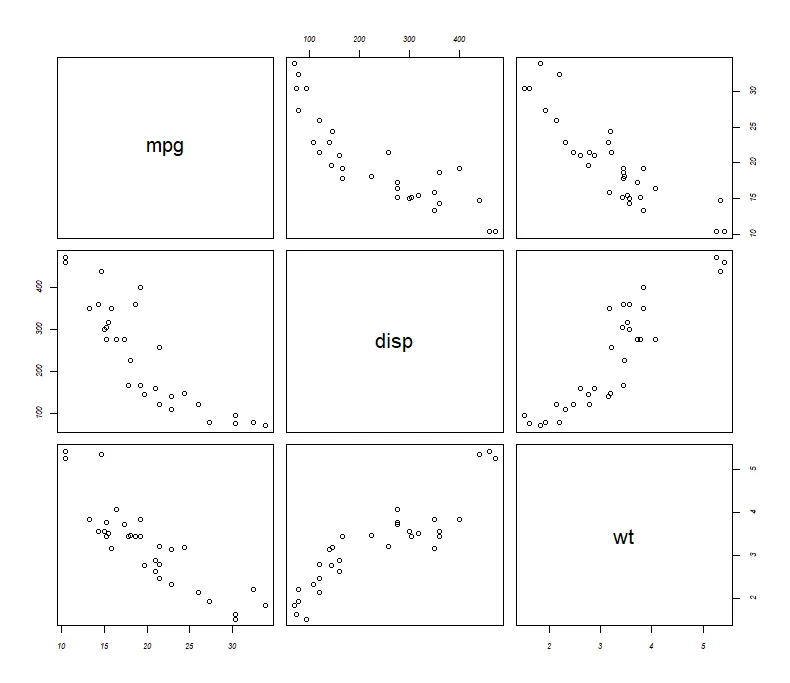
②添加选项upper.panel = NULL将只生成下三角的图形
三维散点图
用scatterplot3d包中的scatterplot3d()函数来绘制三维散点图
scatterplot3d(x, y, z)
install.packages("scatterplot3d")library(scatterplot3d)attach(mtcars)scatterplot3d(wt, disp, mpg,xlab="wt / t", ylab="mpg / Miles per gallon", zlab="disp / Cubic inch")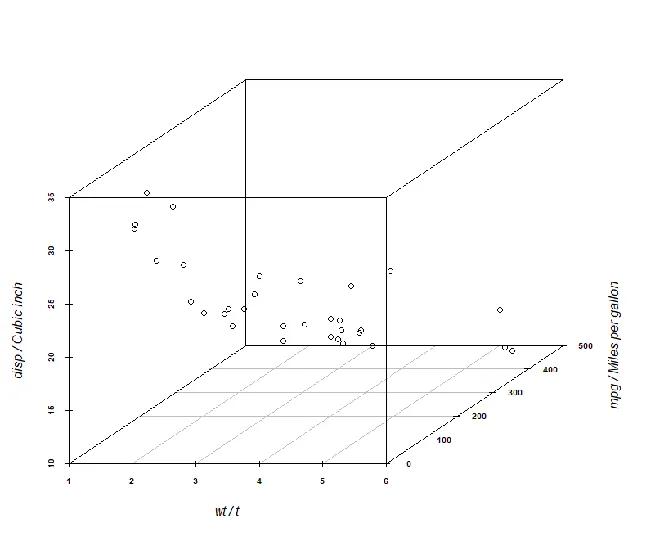
旋转三维散点图
使用rgl包中的plot3d()函数可创建旋转的三维散点图,通过鼠标对图形进行旋转
install.packages("rgl")library(rgl)attach(mtcars)plot3d(wt, disp, mpg,col="red", xlab="wt / t",ylab="mpg / Miles per gallon", zlab="disp / Cubic inch")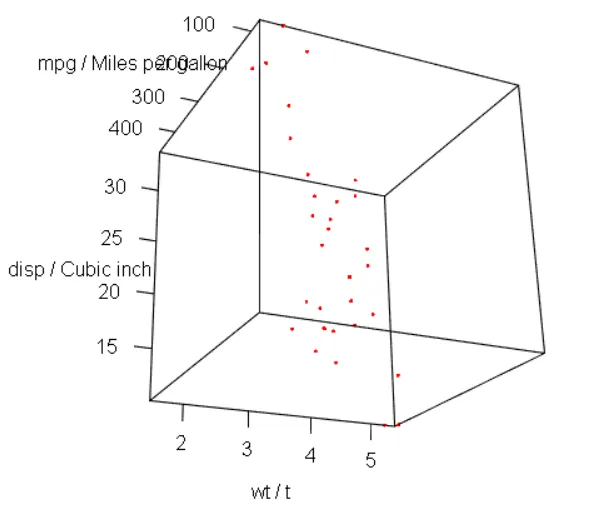
气泡图
展示三个变量间的关系,除了使用三维散点图,还可以使用气泡图来展示。气泡图是先创建一个二维散点图,然后第三个变量的值用点的大小来表示,值越大,气泡越大,反之,越小。
气泡图可以使用使用**函数symbols()**来创建
该函数可以在指定的(x, y)坐标上绘制圆圈图、方形图、星形图、温度计图和箱线图。
symbols(x, y = NULL,
circles, squares, rectangles, stars, thermometers, boxplots, # 圆形,正方形,矩形,星形,温度计、箱形
inches = TRUE, add = FALSE, fg = par(“col”), bg = NA, xlab = NULL, ylab = NULL, main = NULL, xlim = NULL, ylim = NULL, …)
attach(mtcars)symbols(wt,mpg,circles=disp,inches=0.25,bg="lightblue", xlab="wt / t",ylab="mpg / Miles per gallon")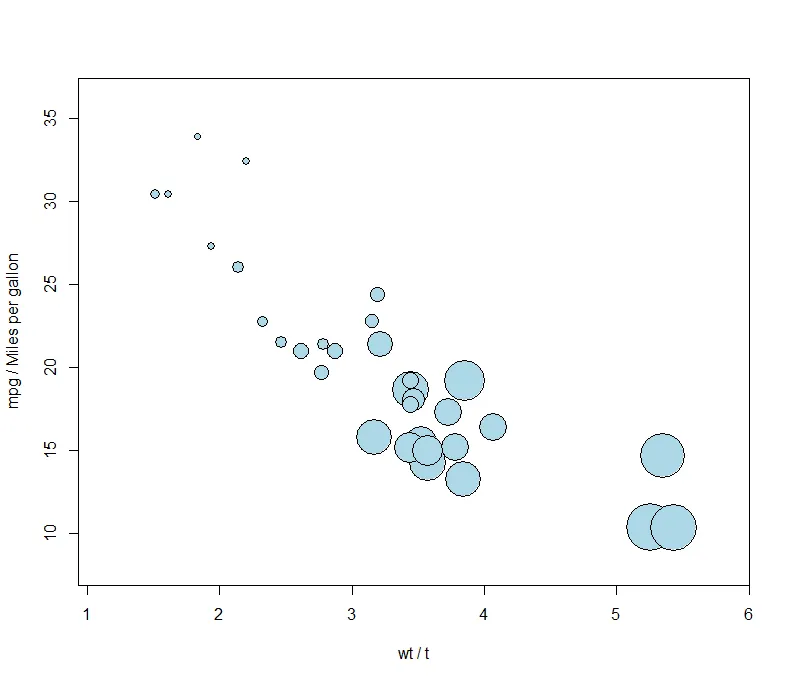
折线图
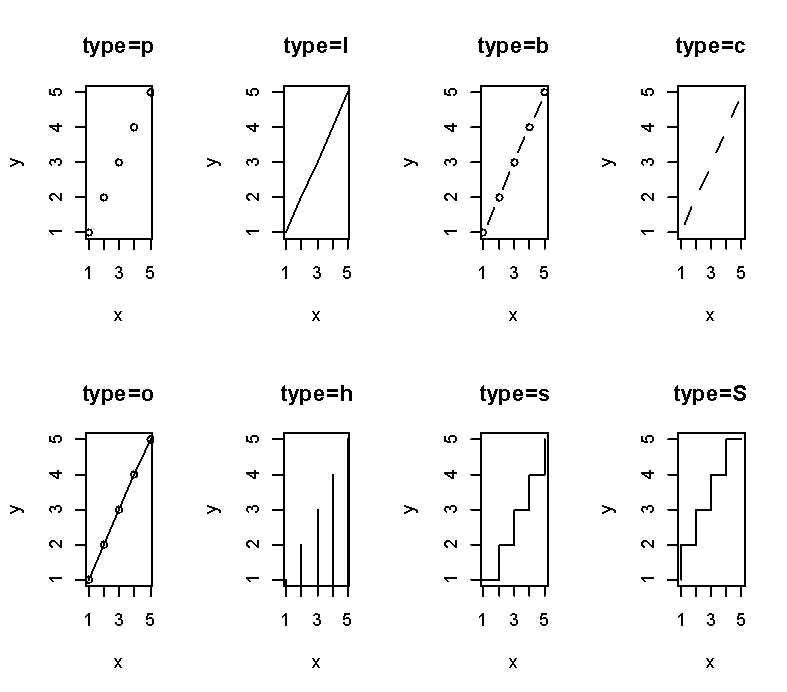
折线图就是将散点图上的点从左到右的连接起来。折线图一般可以用函数plot()和lines()来创建
plot(x, y, type=) lines(x, y, type=)
| 类型 | 描述 |
|---|---|
| p | 只有点 |
| l | 只有线 |
| b | 线连接点 |
| c | 线连接点,但不绘制点 |
| o | 实心点和线(即线覆盖在点上) |
| h | 直方图式的垂直线 |
| S、s | 阶梯线 |
| n | 不生成任何点和线,通常用来为后面的命令创建坐标轴 |
图形组合
在R中,可以使用**函数par()或layout()**将多幅图形组合为一幅图形
par
在par()函数中使用图形参数mfrow=c(nrows, ncols)来创建按行填充的、行数为nrows、列数为ncols的图形矩阵。另外,可以使用mfcol=c(nrows, ncols)按列填充矩阵(几行几列)
attach(mtcars)opar<-par(no.readonly=TRUE)par(mfrow=c(1,2))plot(wt,mpg, xlab="wt / t",ylab="mpg / Miles per gallon")plot(wt,disp, xlab="wt / t",ylab="disp / Cubic inch")par(opar)detach(mtcars)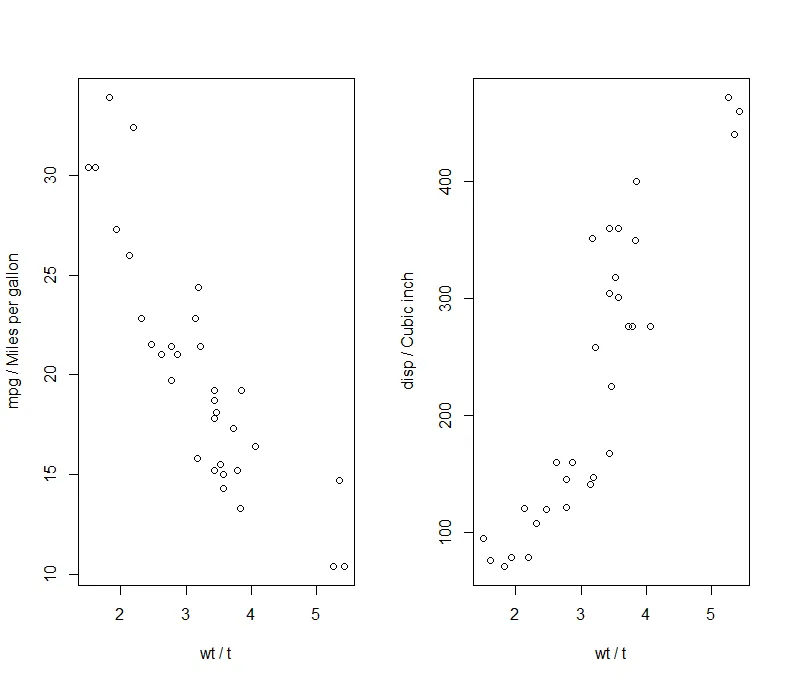
layout
layout(mat,widths=,heights=,byrow=)
其中的mat是一个矩阵,它指定了所要组合的多个图形的所在位置, 非0数字代表绘制图形的顺序,相同数字代表占位符,0代表空缺,不绘制图形。widths = 各列宽度值组成的一个向量,heights = 各行高度值组成的一个向量。byrow=表示图形按行(TRUE)还是按列(FALSE)排列,默认按列排放。
attach(mtcars)layout(matrix(c(1,1,1,1,0,2,0,0,0,0,3,0,0,0,0,4), 4, 4))hist(wt)hist(mpg)hist(carb)hist(disp)detach(mtcars)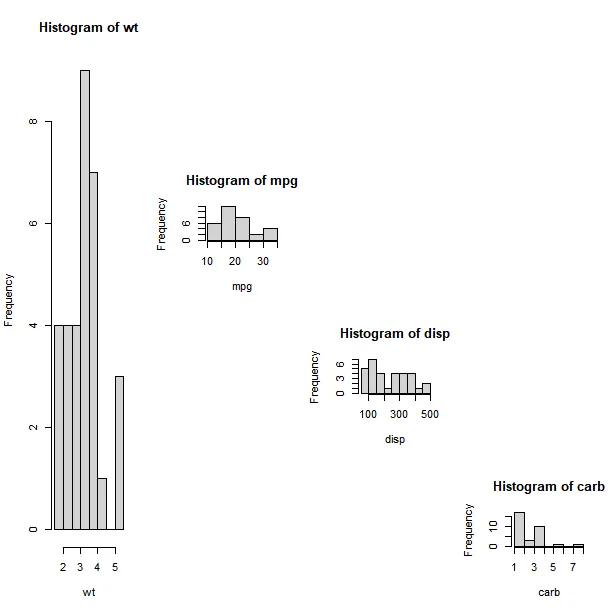
curve
绘制包括直线、幂函数、三角函数和余切函数在内的各种数学图像
curve(expr,from=NULL,to=NULL,n=101,add=FALSE,type=“l”,xname=“x”,xlabe=xname,tlable=NULL,log=NULL,xlim=NULL…)
expr:表达式
from,to:绘图起止范围
n:表示x取值的数量
add
or F表示将绘图添加到已存在的绘图中 type:样式类型
xname
轴变量名称;xlabe,ylabl:标签名称
rect
绘制矩阵
polygon
绘制多边形